이 글은 LS글로벌의 [빅데이터 처리 분석 실무 표준 과정] 교육 중 Hadoop을 Oracle VirtualBox에 설치하는 실습 과정을 AWS에 설치하는 내용으로 정리하였습니다.
[AS-IS]
VM : Oracle Virtualbox + CentOS 6
[TO-BE]
VM : AWS + Amazon Linux AMI 2017.03.1 (HVM), SSD Volume Type – ami-e21cc38c
그리고, 아래와 같이 총 5개의 내용으로 구성되어 있습니다.
1. EC2(Elastic Compute Cloud) 인스턴스 2개 생성
2. 생성된 EC2 인스턴스 접속 방법
3. Hadoop 설치를 위한 기본 환경 설정
4. Hadoop 설치
5. Hive 설치
주의사항

AWS는 Linux t2.micro 1개의 인스턴스 사용시 1개월 실행을 가정하여 12개월 동안 무료로 사용할 수 있습니다.
이번 설치 과정에서는 Linux t2.micro 2개의 인스턴스를 사용하여 Hadoop을 설치할 예정으로 보름(15일) 실행 시 무료입니다. Hadoop 설치 후 해당 인스턴스를 보름(15일) 이상 계속 사용할 경우 요금이 부과될 수 있으니 요금 부과를 원하지 않을 경우 꼭 인스턴스를 Stop 하거나 Terminate 해야 합니다.
1. EC2(Elastic Compute Cloud) 인스턴스 2개 생성
2. 생성된 EC2 인스턴스 접속 방법
3. Hadoop 설치를 위한 기본 환경 설정
4. Hadoop 설치
교육 과정에서는 Hadoop 1.x.x 버전을 설치하였지만 이 문서에서는 Hadoop 2.8.0 버전을 설치하겠습니다. 우선 Hadoop을 설치하기 위해서는 java 가 설치되어 있어야 합니다. 우리가 생성한 인스턴스에 설치된 java 버전을 확인해 보면 OpenJDK 1.7.0_141 버전이 설치되어 있는 것을 알 수 있습니다.
$ java -version


현재 인스턴스에 java는 설치되어 있지만, jps(java virtual machine process status tools) 명령어가 실행되지 않습니다.
$ jps


해당 명령어는 daemon process 상태 확인을 할 수 있는 명령어로 콘솔에서 Hadoop 이 정상적으로 동작하는 지 여부를 확인할 수 있습니다. 해당 명령어가 실행 될 수 있도록 하는 방법은 여러가지가 있지만 간단하게 ant를 설치하는 것으로도 해결할 수 있습니다. 설치 시에는 yum 을 사용합니다.
$ sudo yum install ant

ant 패키지의 내용을 보여주는 화면에서 해당 패키지의 내용이 맞는지 사용자의 선택을 기다리는부분이 나옵니다. ‘y’를 입력하여 다운로드 하여 설치를 진행합니다.



ant 패키지 설치 이후 다시 jps 명령을 실행해 봅니다. 이번엔 정상적으로 해당 명령어가 실행되는 것을 확인할 수 있습니다.
$ jps

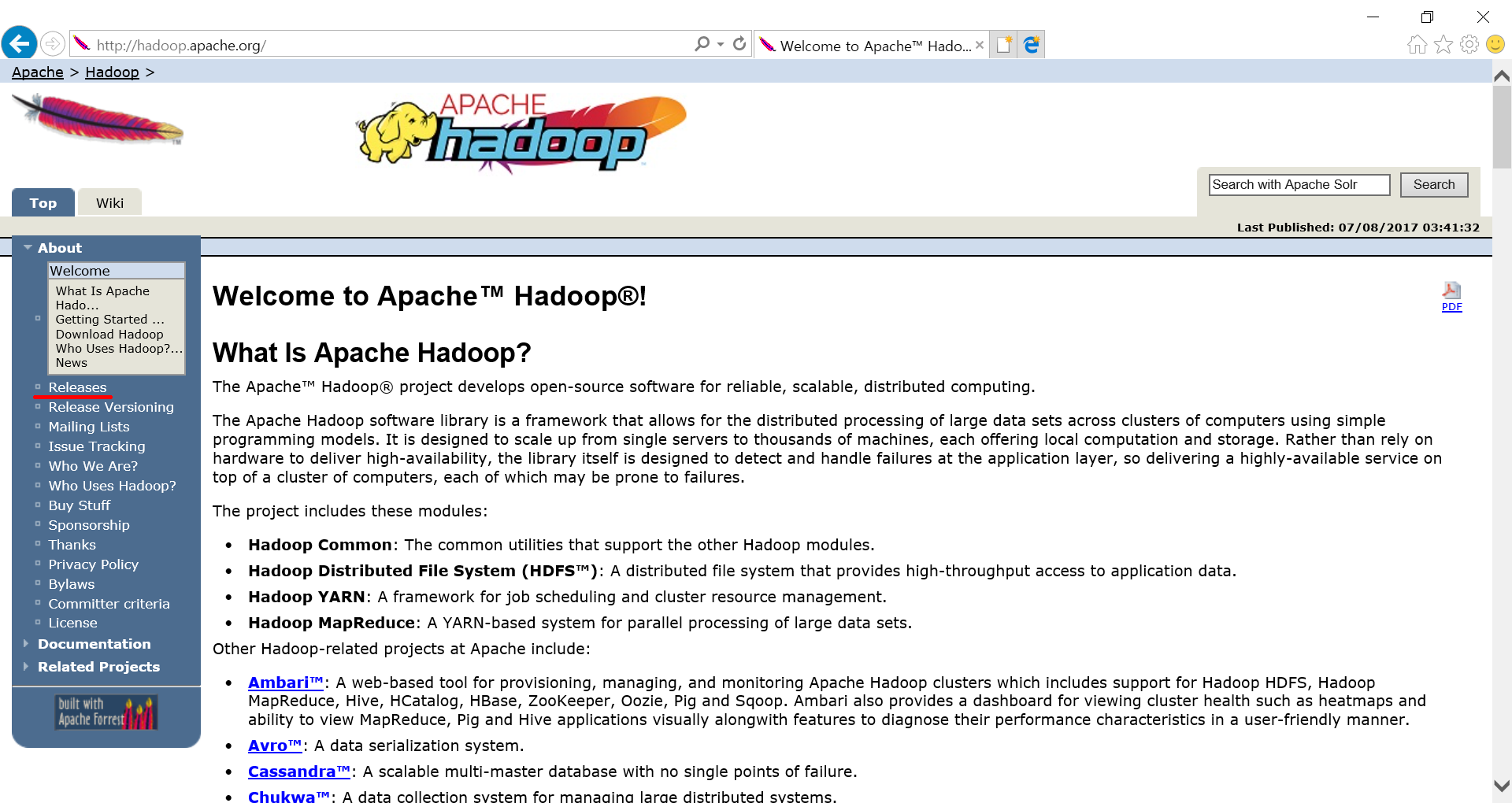
Hadoop 설치 파일의 경로는 아래와 같이 Hadoop 공식 홈페이지에서 확인할 수 있습니다. http://hadoop.apache.org 를 방문 하여 왼쪽 메뉴에서 [Release] 를 클릭합니다. Hadoop Release를 다운로드 받을 수 있는 화면이 나타납니다. 2.8.0 버전의 binary 모드를 다운받기 위해 해당 링크를 클릭합니다.



링크를 클릭 후 나타나는 화면에서 Hadoop 을 다운받을 수 있는 링크를 확인할 수 있습니다.

SERVER1 인스턴스에서 해당 링크의 파일을 wget 으로 다운 받습니다.
$ wget http://apache.tt.co.kr/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz


다운로드가 완료되면 압축을 풉니다.
$ tar xvzf hadoop-2.8.0.tar.gz


압출을 풀면 Hadoop 은 설치가 완료 된 것입니다. Hadoop이 설치된 경로의 접근을 쉽게 하기위하여 PATH를 설정합니다. 환경설정을 할 수 있는 방법도 여러가지가 있지만, 우리는 교육 과정에서 진행한 방법과 동일하게 /etc/profile 을 수정하여 설정된 PATH가 적용될 수 있도록 합니다.
/etc/profile 을 vi 편집기로 엽니다.
$ sudo vi /etc/profile

제일 마지막 줄에 아래와 같이 추가합니다. 첫 번째 줄은 HADOOP_HOME 경로를 지정하는 것이며, 두 번째, 세 번째 줄은 명령어 실행을 어느 위치에서나 할 수 있도록 하기 위한 PATH 설정입니다.
export HADOOP_HOME=/home/ec2-user/Hadoop-2.8.0 export PATH=$HADOOP_HOME/bin:$PATH export PATH=$HADOOP_HOME/sbin:$PATH

변경된 설정 내용을 즉시 반영하기 위하여 source 명령을 사용합니다.
$ source /etc/profile

Hadoop 실행 환경 준비를 위하여 몇몇 파일(core-site.xml, hdfs-site.xml, slaves)을 수정해야 합니다. 해당 파일이 있는 경로로 이동합니다.
$ cd $HADOOP_HOME/etc/hadoop

core-site.xml를 vi 로 열어 <configuration>…</configuration> 내용을 아래와 같이 수정합니다.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://SERVER1:9000</value> </property> </configuration>


hdfs-site.xml를 vi 로 열어 <configuration>…</configuration> 내용을 아래와 같이 수정합니다.
asdf sdf <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>


slaves를 vi 로 열어 localhost로 되어 있는 부분을 SERVER1, SERVER2로 변경합니다.
SERVER1 SERVER2



여기까지 SERVER1에 Hadoop 설치파일을 다운로드 받은 후 압축을 풀고 환경설정까지 완료하였습니다. 동일한 방법으로 SERVER2에도 할 수 있지만, 간단히 scp 명령을 통해서 SERVER1에 진행한 Hadoop 파일을 그대로 SERVER2에 복사할 수 있습니다. (SERVER1에서 추가한 /etc/profile 파일도 SERVER2로 복사해서 사용해도 됩니다.)
$ scp -r hadoop-2.8.0 SERVER2:/home/ec2-user/


복사가 완료되면 SERVER2에 접속해서 정상적으로 복사되었는지 확인 해 봅니다.
Hadoop을 실행하기 전에 먼저 Name node(SERVER1)에 HDFS를 포맷해야 합니다.
$ hdfs namenode -format


이제 start-dfs.sh 쉘 스크립트 명령어를 실행하여 Hadoop 클러스터를 시작 합니다.(시작 후 중지할 때는 stop-dfs.sh 명령어 입니다.)
$ start-dfs.sh


jps 명령을 통해 정상적으로 동작 여부를 확인합니다. NameNode, DataNode, SecondaryNameNode 의 프로세스를 확인할 수 있습니다.
$ jps

아래 명령어를 통해 Hadoop 설치를 확인할 수도 있습니다.
$ hdfs dfsadmin -report


또, Name Node(SERVER1)의 50070 포트로 http 접속을 하여 웹 화면으로도 확인할 수 있습니다.
http://13.124.185.233:50070

이상으로 AWS에 Hadoop 설치를 모두 마쳤습니다.